Replacing ExecuteCommand with ExecuteHTTPRequest in IBM PA V12
The following is a technical note discussing the replacement of ExecuteCommand with ExecuteHTTPRequest in the migration from IBM Planning Analytics...
5 min read
This technical note outlines the method for embedding the OpenAI API into a TI script in IBM Planning Analytics. The purpose of this exercise is to integrate external data using the OpenAI API to pull live estimates into IBM Planning Analytics. This can be applied to several use cases, where existing data in IBM PA can be enriched with external data to provide additional analytical insight or improve modeling and forecast accuracy.
This integration leverages the ExecuteHTTP function. This function is only available in Planning Analytics Server version 12. For any current V11 and prior implementations, you will need to offload this work to a dedicated executable on the server and continue to use ExecuteCommand.The following example leverages AI-generated estimates to supplement existing external datasets. The specific API you use to call an LLM for your business use case will vary based on the kind of output you are looking to receive from the various LLMs. The current frontier offerings from Anthropic, OpenAI, and Google are all comparable on the API integration side. However, there are differences in the kind of output you will receive from the models these providers have to offer. For example, OpenAI models are generally more creative and freeform, while Anthropic models adhere more strictly to the prompt and follow instructions very well. The API you decide to use for your business use case should be governed by cost, intended use case, and planned future improvements. The landscape is also changing day by day, so it is best to remain agile in implementations using LLM APIs in the event that there is a clear winner in the future.
Out of the box, the OpenAI API answers queries based on its pretrained data. The API offers the capability for fine-tuning, web search, and tool integration that can and should be tailored to the specific implementation. The benefit of this form of data enrichment and supplementary estimation is that it allows Planning Analytics users to generate external datasets quickly and cost-effectively without having to pay for multiple data subscriptions that offer API access. If you wanted to create a dataset of CPI and average temperature to run forecasting models on your enterprise data, you would need multiple data subscriptions and customized request handling for every API you intend to use. With a solution like this, you can generate quick directional estimates in support of forecasting for a large variety of metrics.
In addition to generating estimates of future tariff rates, fuel prices, weather data, etc, you can also decide later that you would like to architect a data pipeline for accurate real-time data. The benefit of this solution is its flexibility: you can decide you want to see your data’s correlation with some arbitrary external variable and change a prompt in seconds to estimate the data. If there is still a need for more accurate information, you now have a working proof of concept to justify acquiring a new data source.
You can also continue using dedicated APIs to pull external data, while using an LLM API to quickly autofill missing historical data in a dataset. For example, popular weather APIs often offer lower subscription tiers if you only need access to current weather data. You could implement direct integration with real-time weather updates and use an LLM API to automatically autofill historical data and fix future gaps in the dataset.
Firstly, we need to understand how best to communicate with the OpenAI API. Using Postman, I tested a request to the chat completions endpoint with the following request body:
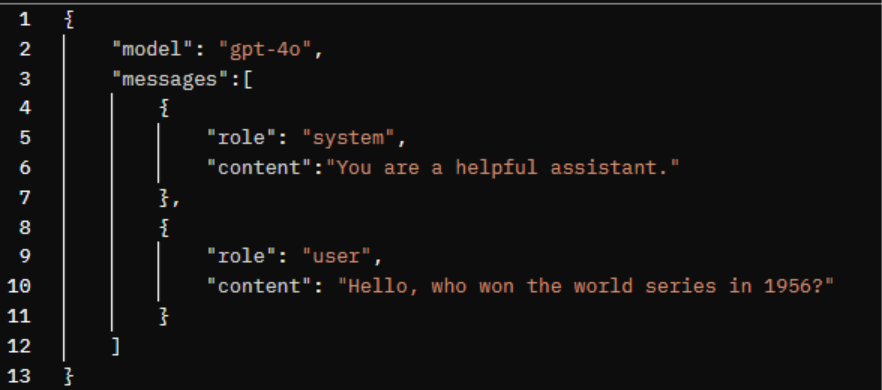
Request details:
I received the following output:
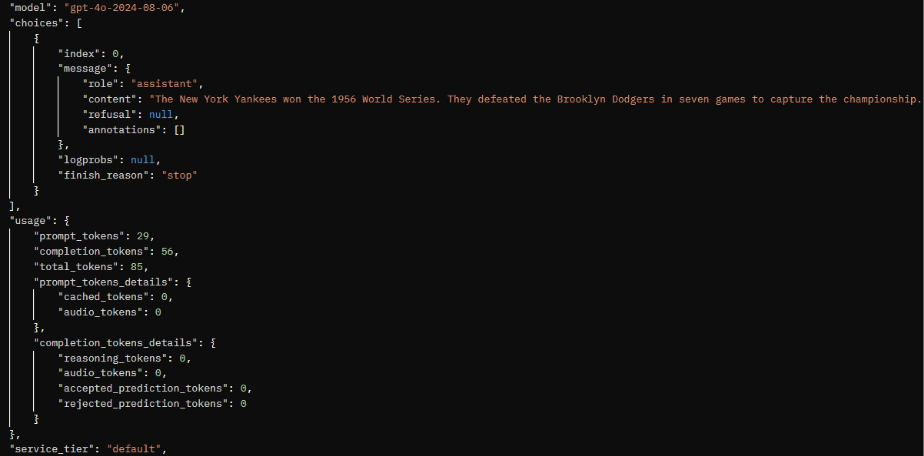
While this will vary by the specific nature of the API or external system, we now know how OpenAI expects our request to arrive, and the kind of response structure we will receive. We can specify: the model we would like to use, some basic system instructions, and the actual prompt we would like a response to. In the accompanying response, we need to take note of the key value pairs we will need to extract. In this case, we need to locate ‘content’ in our response. With this out of the way, we can create a new TI process that replicates this interaction with ExecuteHTTPRequest.
Step 2: Prolog - Setup and Configuration
In the prolog, we initialize variables for our API key to OpenAI’s API and the system instructions for the LLM. In the following example, we are asking the LLM to provide data estimates with no additional text to cut down on the string parsing we will need to do later. This system context will remain consistent across all sent requests, so it makes the most sense to set it here along with our authentication credentials. For this demo I have elected to store the OpenAI API key in a control cube on the server (defer to your own best practices for secrets management in production environments).

Now we can walk through our data source view and find any intersections with missing or incomplete data. These intersections can be used to build our prompt to the LLM in the HTTP request body.
Step 3: Data - Dynamic Query Construction
Now, we will loop through our data source and construct a dynamic prompt at each missing cell.
This example uses a simple cube called ‘City Stats’ that stores precipitation and temperature information by city and period. We are going to loop through the source view to locate missing temperature information, then send a query to our LLM and write the response back to our cube.

You will notice that we must do string parsing on JSON without any external libraries to build the request and extract the response. This can be quite tedious, but the output format for this API does not change when querying this endpoint. In this way, we can safely plan to locate the key ‘content’ and write the value of that pair back to our cube. (NOTE: See update related to JSON support at the end of this post.) Now, let’s test this process on a single data point. From my existing dataset I deleted our temperature entry for Tokyo in July.
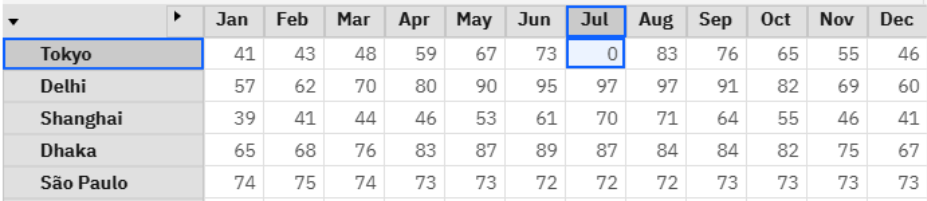
Here, I add some temporary logging to verify that our request is handled successfully and run the process.
![]()
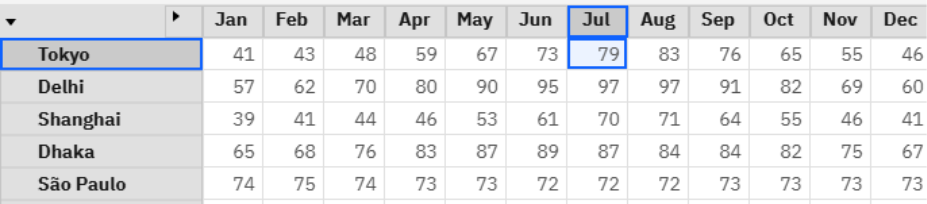
Success! We now have a process that can be executed ad-hoc or via Chore that will check this cube for missing data points and quickly estimate relevant metrics based on the specific dimension intersection of the missing data. This is a functional and relatively clean implementation. However, there is a key efficiency issue. We are making one API call per missing data point.
Step 4 - Performance and Cost Optimization
In this example, 50 cities and 12 months give us a maximum number of 600 API calls to OpenAI. Since requests to LLM APIs charge by input and output token, it would be best to cut down on the number of sent instructions and queries to keep our API usage low and significantly reduce the overhead on running the process for many missing data points. The idea is to collect missing data point intersections until we reach a defined ‘batch-size’, then send a query to the LLM like, “What is the temperature in March, April, and October in Chicago IL?” So long as our system instructions are followed, we receive a comma-separated list of data points that we can parse back into individual data points and write to the cube. The technical challenge here is maintaining lists of items that are stored in long strings and iterating through them to write back values while handling whitespace inconsistencies and edge cases.
This batch processing comes with the same string parsing tribulations as the JSON configuration earlier but leaves us with a standalone TI process that can leverage frontier AI models to estimate data points much quicker than any manual alternatives. In two of my own use cases, I observed speed increases of eight to tenfold and an average API cost reduction of 85% when processing queries in batches of 10. The only tradeoff lies in implementation complexity. You will need: variables to accumulate batches during iteration, logic to trigger an API call when a batch is full, parsing code to map responses to dimension elements, and epilog handling for the final incomplete batch.
Ultimately, this integration pattern provides Planning Analytics users with an agile, cost-effective method for data enrichment or quick estimation leveraging modern LLM APIs. This offers Planning Analytics users the ability to quickly produce external datasets for forecasting while retaining the option to upgrade to authoritative sources as business requirements evolve.
Please contact us at solutions@acgi.com if you have questions or if you have a use case that you would like to discuss in more detail.
UPDATE 11-18:
Basic JSON support has been added to Planning Analytics Server in version 12.4 and later. This makes building requests and parsing responses much more straightforward. Refer to the following documentation for more details: JSON Functions - IBM Documentation.
